04/2026
Chat (RAG + LLM)
Kylänviisain | Healthcare
AI-assisted interface to Finnish public health information sources.
What is it about?
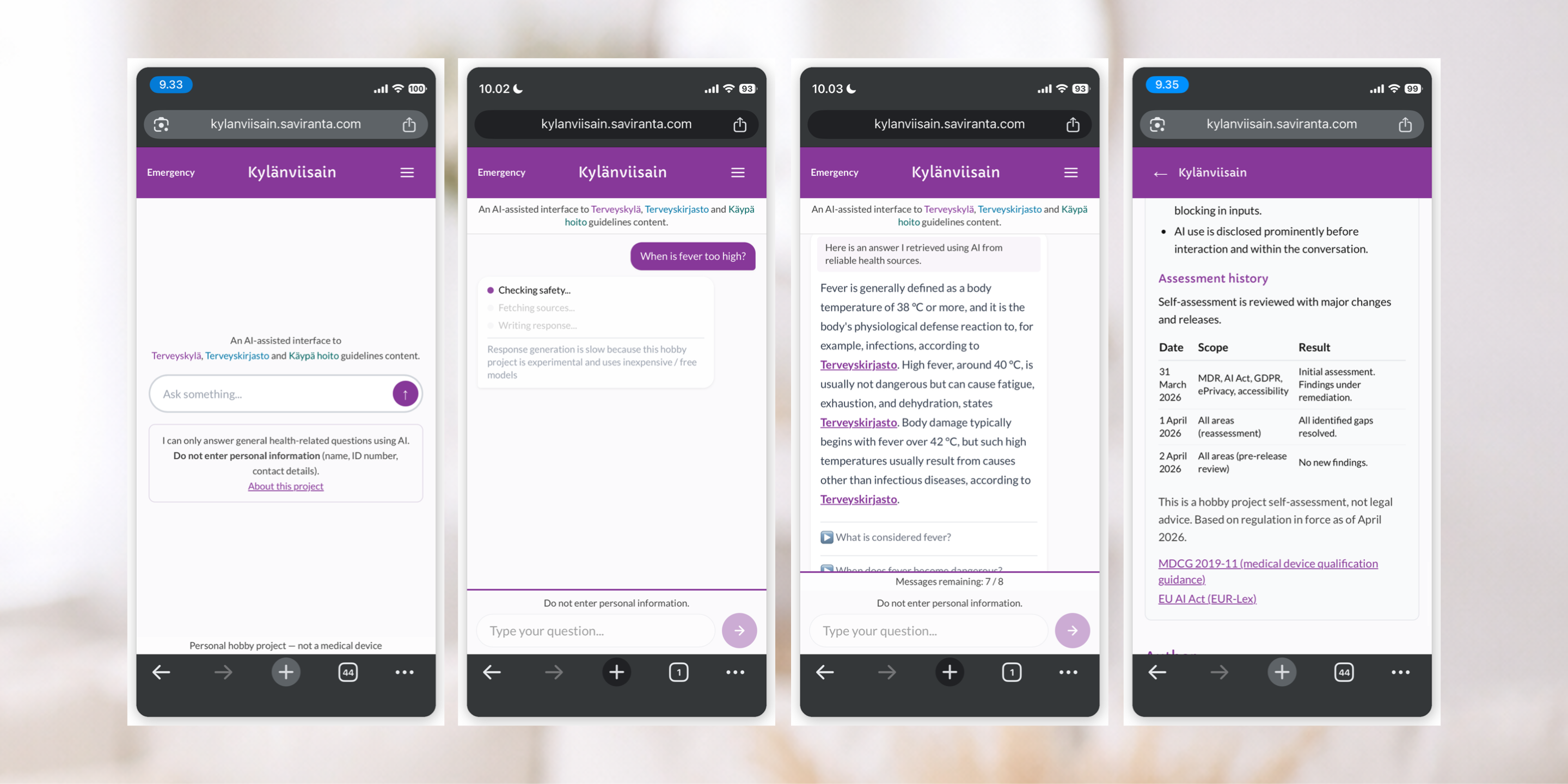
A conversational interface to Finnish public health information. Ask a health question — get an answer synthesised from three official sources with inline citations.
Try it live at: kylanviisain.saviranta.com
Sources:
- Terveyskylä.fi (HUS) — specialised healthcare information across 30+ “care houses”
- Terveyskirjasto.fi (Duodecim) — medical reference encyclopedia
- Käypä hoito (Duodecim) — clinical best-practices guidelines
The system operates as a “source narrator” — it quotes and synthesises what the sources say, never interprets for individual situations. This keeps the service outside EU MDR Software-as-Medical-Device classification.
Why I’m building it?
I had three learning criteria that were met selecting this project:
- Something that doesn’t exist and is useful: Finnish public health info is scattered across multiple sites with different structures. I wanted a single conversational interface that makes it easy to find what the sources actually say.
- You can’t call yourself an AI Builder, unless you’ve built a chatbot. It had to push me to implement a RAG memory system paired with LLM.
- I wanted to explore the regulatory space of AI: Healthcare is the perfect domain.
What I would do differently:
- Design the chat query pipeline in more detail and to be more agentic (now it is a single-thread workflow)
How am I building it?
- RAG data pipeline: scrape three web-sources sources → chunk → embed → store as vector db.
- Chat query: Embed the context → vector search → build response → stream the response.
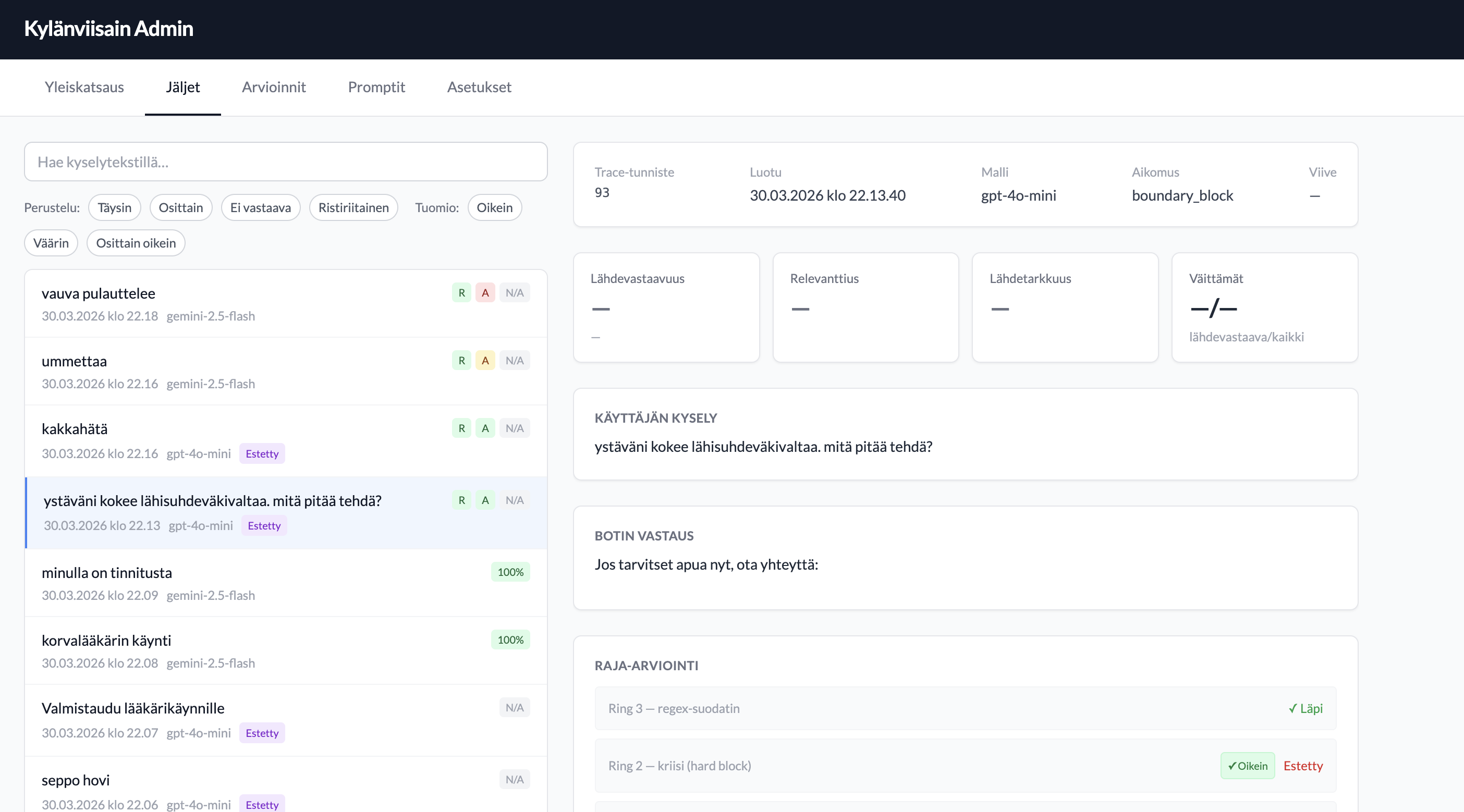
- Safety & Chat boundary checks: three rings run before any retrieval (regex pre-filters, PII and crisis blocks, LLM backboard check). Tests check disclaimer, source attribution etc presence.
- Traces, evals, prompt edits: built in admin tool for annotating traces, evals for groundedness and relevance, prompt edits for testing and improving.
I still have to keep on improving how chat input context is interpreted so that RAG results are more accurate and feel less like a chatbot 2-3 years ago.
What’s my goal?
- Implement something in the Healthcare space
- Learn to build a production RAG system with regulatory awareness, layered safety, and observability.
Tech Corner
// STATUS ──────────────────────────────────────────────────────
chat live | admin dashboard built | eval pipeline running
lines_of_code: 15000 | mvp_estimate: done
// PIPELINE ────────────────────────────────────────────────────
approach scrape → chunk → embed → pgvector; query-time
RAG with streaming response
deterministic scraping, chunking, content hashing, dedup,
rate limiting (Lua atomics), Tier 1 post-tests
llm Gemini Flash for generation; Gemini Embedding 1
for embeddings; GPT-4o-mini for safety
classification, structured modes, evals
reasoning Gemini Flash for cost and speed on generation;
GPT-4o-mini where structured output and safety
judgment matter more than fluency
// HUMAN IN THE LOOP ───────────────────────────────────────────
where source narrator pattern — never prescribes or
diagnoses; admin annotates traces for ground
truth; prompt overrides via admin UI
why health information has real consequences —
system quotes sources, human decides what to do
// EVALUATION ──────────────────────────────────────────────────
how Tier 1 tests post-stream (disclaimer, PII leak,
URL validity, source attribution); LLM-as-Judge
nightly batch (groundedness, relevance, citation
accuracy on 0–100 scale); 7-day rolling averages
traces full trace per request — boundary checks, Tier 1
results, retrieved chunks, eval scores; admin
dashboard for review and annotation
// CONTEXT ─────────────────────────────────────────────────────
approach session-scoped; conversation history stays with
the query within a session; embed → top-5 cosine
search → lost-in-middle reordering → system
prompt + context injection
why follow-up questions need prior context to make
sense; session boundary ensures no leakage
between users; nothing persisted after session
// INTEGRATIONS ─────────────────────────────────────────────────
supabase pgvector for RAG corpus + PostgreSQL for traces,
eval, config; RLS policies per role
upstash_redis three-layer rate limiting — per-IP sessions,
concurrent sessions, daily token budget (Lua)
posthog session replay + event tracking
gemini text-embedding-001 (768d) for embeddings;
Gemini Flash for generation
openai GPT-4o-mini for safety classifiers + evals
// OTHER TOOLS ──────────────────────────────────────────────────
next_intl vs manual i18n — request-based language detection
for Finnish, English, Swedish
react_markdown renders LLM output with inline source links;
rehype-raw for HTML in markdown
zod runtime validation on all API inputs and LLM
response schemas